MLA -- Regularization Lasso Regression
"What is the lasso regression? Add L2 norm into loss function."
Norm is a commonly used concept in mathematics, which is also often encountered in machine learning.
The first thing that needs to be clear is that Norm is a function. We usually use it to measure the value of the vector in machine learning. The norm is defined as:
Common Norm:
-
Norm:
When p is 2, Norm is also called Euclidean norm. It represents the distance from the original to the points determined by the vector x. It is applied very frequently in machine learning. -
Square Norm:
It is square of norm, $ |x|_2^2$. The advantage is that it is obviously easier to calculate, which can be simply calculated by the dot product of . -
Norm:
In some case, Norm is not very popular, because it grows very slowly near the origin. Sometimes, it is important to distinguish elements that happen to be zero and non-zero but have very small value. In this case, we can use Norm: -
Norm:
It is also called Maximum norm, which is the absolute value of the element with largest amplitude in the vector:
Regularization in Regression
1. Linear Regression Review
The norm form of linear regression:
The loss function that we need to minimize:
- Gradient Descent:
- Least Square:
2. Ridge Regression Review
Since applying linear regression directly may produce verfitting problem, we need to add the regularization term. When Norm is added, it is called Ridge Regression.
is the constant coeffient, which is used to adjust the weights of linear regression term and regularization term.
is the L2 norm of vector.
Ridge Regression is very simialr to normal linear regression.
- Gradient Descent:
- Least Square:
Ridge regression reduces the regression coefficients without abandoning any variables. When the coefficient is close to 0, it is equivalent to weakening the significance of its feature. But this model still has a lot of variables, and the model is poorly interpretable.
Is there a compromise? That is, it can prevent overfitting and overcome the shortcomings of the Ridge regression model with many variables? Yes, this is the Lasso regression mentioned below.
2. Lasso Regression
Similar as Ridge Regreesion, Lasso Regression also adds a Norm term in the loss function to try to avoid overfitting. When Norm is added, it is called Lasso Regression.
m is the count of sample data.
is the constant coeffient, which is used to adjust the weights of linear regression term and regularization term. It needs to be tuned.
is the L1 norm of vector.
Lasso regression makes some coefficients smaller, and even some coefficients with smaller absolute values directly become 0, so it is especially suitable for the reduction of the number of parameters and the selection of parameters, so it is used to estimate the linear model of sparse parameters.
However, there is a big problem with Lasso regression. Its loss function is not continuous and differentiable. Since the L1 norm uses the sum of absolute values, the loss function is not derivative. That is to say, Least Square method, Gradient Descent method, Newton method and Quasi-Newton method all failed in this case. So how can we find the minimum value of the loss function with this L1 norm?
There are two new methods to get extreme value:
- Coordinate Descent
- Least Angle Regression, LARS
3. Coordinate Descent method for Lasso Regression
As the name suggests, Coordinate Descent is the descent in the direction of the coordinate axis, different from the gradient direction in the gradient descent. But both are iterative methods in a heuristic way.
Algorithm Process:
- Intialize as . 0 represents the current iteration is 0.
- In k-th iteration, we calculate started from to :
>In this case, $J(\theta)$ only has one variable $\theta_i$, and others are all constant. Hence, the minimum value of $J(\theta)$ can be easily obtained by differentiation.
Let's be more specific, in k-th iteration:
- Comparing the vector with vector, if the changes are small enough, then is the final return. Otherwise, jumping to Step 2 and continuing (k+1)-th iteration.
4. Least Angle Regression method for Lasso Regression
Before introducing Least Angle Regression, let ’s look at two preliminary algorithms:
(Unfinished)
4.1 Forward Selection Algorithm
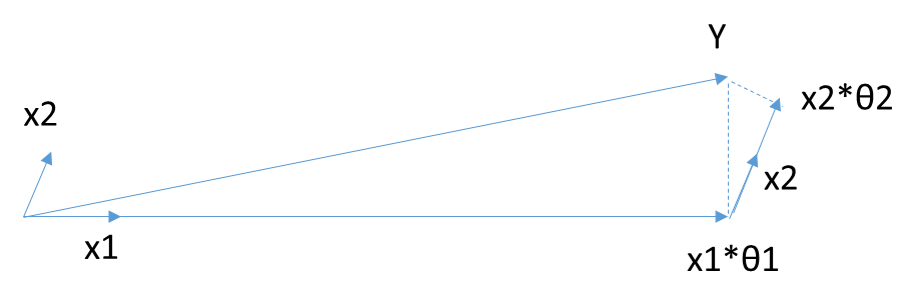
4.2 Forward Stagewise Algorithm
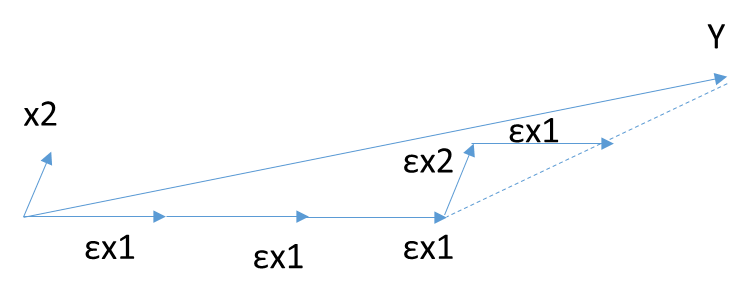
4.3 Least Angle Regression Algorithm (LARS)
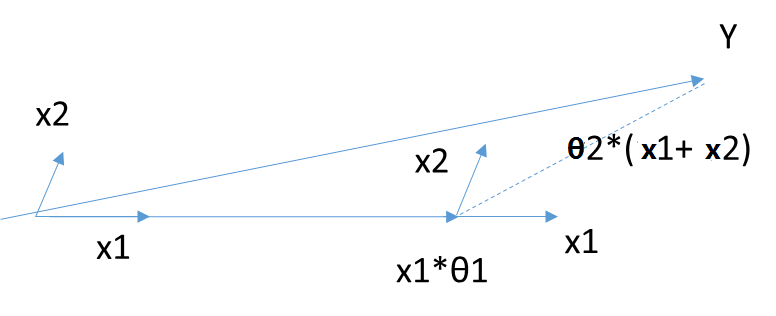
5. Conclusion
Reference: