Text Analysis -- NLTK's vader library
"Topic: How does NLTK's vader library work to calculate sentiment value for text?"
Topic: How does NLTK's vader library work to calculate sentiment value for text?
Overview
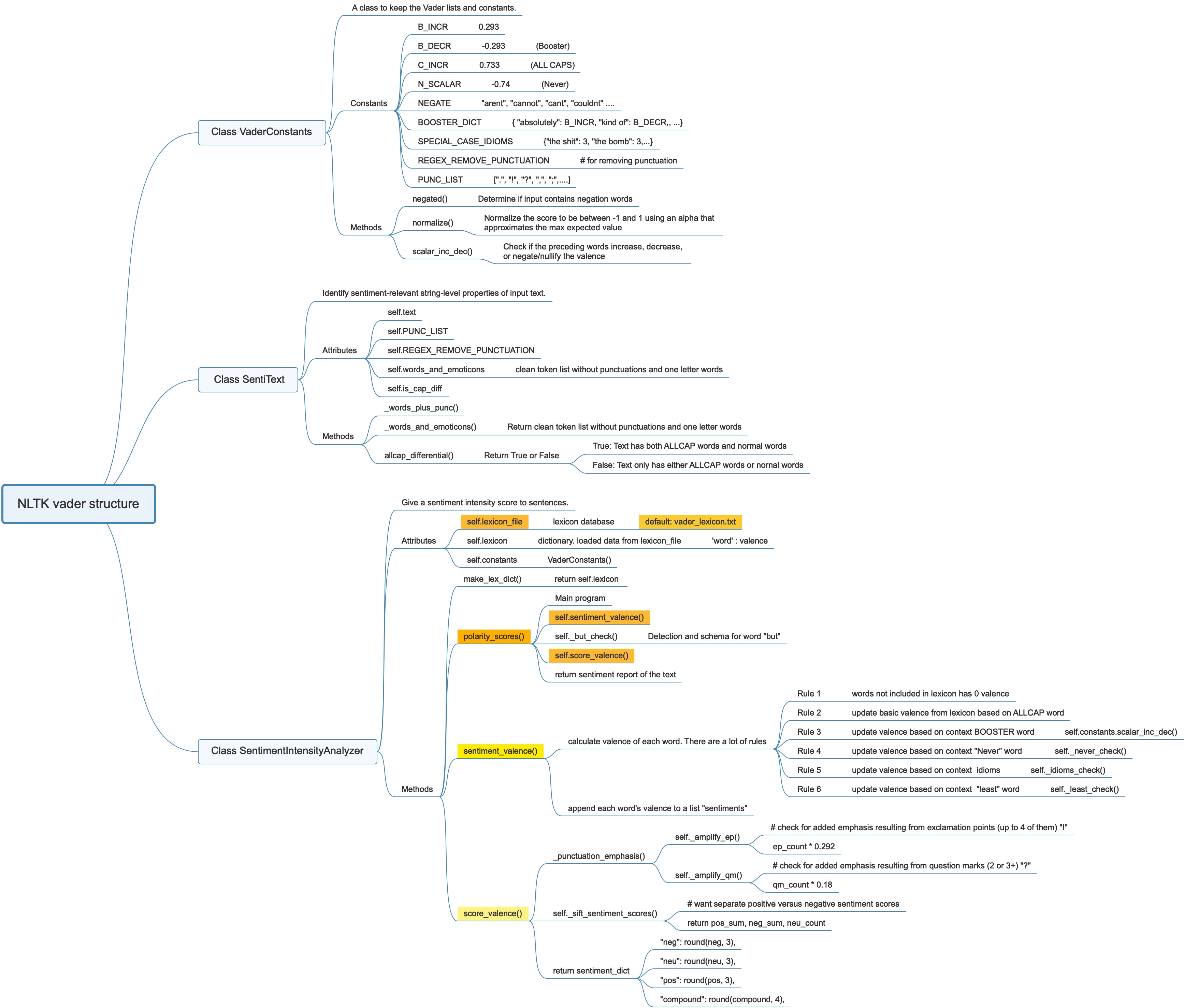
NLTK's vader tool is mainly used to judge the sentiment polarity of a text: positive, negative or neutral. From its code design perspective, the vader is more suitable for analyzing short social media text sentiment analysis. The most important part of vader is class SentimentIntensityAnalyzer, and the core methods of this class are polarity_scores(), sentiment_valence() and score_valence().
One simple example of using vader
from nltk.sentiment.vader import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
sentiment = analyzer.polarity_scores(text)
As we all know, the first "import" statement imported “SentimentIntensityAnalyzer” class, and then we can use the methods of this class to calculate the text sentiment value.
Next, we initiate a new instance "analyzer" of class "SentimentIntensityAnalyzer".
Finally, we call the methods "polarity_scores()" in this instance "analyzer".
Therefore, we can easily find out that the most critical question is what algorithm is included in the last method "polarity_scores()"?
At first what is the content of this class?
Class "SentimentIntensityAnalyzer"
class SentimentIntensityAnalyzer:
"""
Give a sentiment intensity score to sentences.
"""
def __init__(
self, lexicon_file="sentiment/vader_lexicon.zip/vader_lexicon/vader_lexicon.txt",
):
self.lexicon_file = nltk.data.load(lexicon_file)
self.lexicon = self.make_lex_dict()
self.constants = VaderConstants()
def make_lex_dict(self):
"""
Convert lexicon file to a dictionary
"""
lex_dict = {}
for line in lexicon.split("\n"):
# Only get "word" and "sentiment value" two data #
(word, measure) = line.strip().split("\t")[0:2]
lex_dict[word] = float(measure)
return lex_dict
def polarity_scores(self, text):
"""
Return a float for sentiment strength based on the input text.
Positive values are positive valence, negative value are negative
valence.
"""
...
return self.score_valence(sentiments, text)
def sentiment_valence(self, valence, sentitext, item, i, sentiments):
...
return sentiments
def _least_check(self, valence, words_and_emoticons, i):
# check for negation case using "least"
...
return valence
def _but_check(self, words_and_emoticons, sentiments):
...
return sentiments
def _idioms_check(self, valence, words_and_emoticons, i):
...
return valence
def _never_check(self, valence, words_and_emoticons, start_i, i):
...
return valence
def _punctuation_emphasis(self, sum_s, text):
# add emphasis from exclamation points and question marks
...
return qm_amplifier
def _sift_sentiment_scores(self, sentiments):
# want separate positive versus negative sentiment scores
...
return pos_sum, neg_sum, neu_count
def score_valence(self, sentiments, text):
...
return sentiment_dict
This class needs one argument -- lexicon_file, which is a database of sentiment values for each word and emoticon. It uses nltk's own database by default, but we can also replace our database as needed. The database has at least two columns, the first column is the word and the second column is the sentiment value. We can see what the database -- vader_lexicon.txt looks like at the end of this article.
This class also has 10 methods inside.The method starting with underscore _ is generally a method used internally by this class, and generally does not need to be called separately by the user. We can also roughly guess from their names "_xxx_check" that their meaning is the detection and corresponding scheme of the special grammar of text, such as but, never or adjective-est, etc.
So we can currently focus our main attention on this four methods:
- polarity_scores() # main program, which is called mostly by users
- make_lex_dict()
- sentiment_valence()
- score_valence()
Before starting to study the algorithm of this method, we must figure out what the two properties of this class generated in the constructor are.
- self.lexicon & self.constants
self.lexicon is generated by loading the word sentiment database and processing with the method make_lex_dict(). And self.lexicon is a dictionary, key and value pair is "word or emoticon" and "sentiment value (a float number)"
self.constants is a instance of the class VaderConstants(), which defines some special values, and syntax, such as booster words, emphasize words and idioms. They are mainly used in the check method. The content of class VaderConstants() will be released later.
1. Method "polarity_scores()":
def polarity_scores(self, text):
"""
Return a float for sentiment strength based on the input text.
Positive values are positive valence, negative value are negative
valence.
"""
# text, words_and_emoticons, is_cap_diff = self.preprocess(text)
sentitext = SentiText(text, self.constants.PUNC_LIST,
self.constants.REGEX_REMOVE_PUNCTUATION)
sentiments = []
words_and_emoticons = sentitext.words_and_emoticons
for item in words_and_emoticons:
# Traverse each takens as 'item'
valence = 0
i = words_and_emoticons.index(item)
# if we need index, why not "for i, item in enumerate(words_and_emoticons):"
if (
i < len(words_and_emoticons) - 1
and item.lower() == "kind"
and words_and_emoticons[i + 1].lower() == "of"
) or item.lower() in self.constants.BOOSTER_DICT:
# if exists "kind of" or current item is a "booster word"
# current item (token) sentiment is 0
sentiments.append(valence)
continue
sentiments = self.sentiment_valence(valence, sentitext, item, i, sentiments)
sentiments = self._but_check(words_and_emoticons, sentiments)
return self.score_valence(sentiments, text)
sentitext is a new instance of the class "SentiText", which is a small class used to Identify sentiment-relevant string-level properties of input text and Clean the text.
words_and_emoticons is a clean list of tokens without symbols, but emojis tokens are still retained. (This is also the significance of the existence of the _words_plus_punc() method when you call the _words_and_emoticons() in the SentiText class)
Then we start to traverse the clean words_and_emoticons list, and then judge the sentiment value of each token in turn. If current word is "kind" and next word is "of" or the word is a booster word, the sentiment of the current word is 0. If the above special conditions do not exist, we continue to call another method sentiment_valence(valence, sentitext, item, i, sentiments). So far, the valence is 0; item is the current word; i is the index of current word in the text; sentiments is a list of sentiment values up to the previous word.
When we get the list of sentiment values for all words, we call a but check method and update a new list of the sentiments.
Finally, we return an answer generated by method score_valence().
So now we need to know what method sentiment_valence() and method score_valence() are
Remember: we don't remove all stop words in this situation. And before calculating sentiment value, this method has already remove all puctuations in the text and all words with 1 letter.
2. Method "sentiment_valence()":
def sentiment_valence(self, valence, sentitext, item, i, sentiments):
is_cap_diff = sentitext.is_cap_diff
words_and_emoticons = sentitext.words_and_emoticons
item_lowercase = item.lower()
if item_lowercase in self.lexicon:
# get the sentiment valence
valence = self.lexicon[item_lowercase]
# check if sentiment laden word is in ALL CAPS (while others aren't)
if item.isupper() and is_cap_diff:
if valence > 0:
valence += self.constants.C_INCR
else:
valence -= self.constants.C_INCR
for start_i in range(0, 3):
if (
i > start_i
and words_and_emoticons[i - (start_i + 1)].lower()
not in self.lexicon
):
# dampen the scalar modifier of preceding words and emoticons
# (excluding the ones that immediately preceed the item) based
# on their distance from the current item.
s = self.constants.scalar_inc_dec(
words_and_emoticons[i - (start_i + 1)], valence, is_cap_diff
)
if start_i == 1 and s != 0:
s = s * 0.95
if start_i == 2 and s != 0:
s = s * 0.9
valence = valence + s
valence = self._never_check(
valence, words_and_emoticons, start_i, i
)
if start_i == 2:
valence = self._idioms_check(valence, words_and_emoticons, i)
# future work: consider other sentiment-laden idioms
# other_idioms =
# {"back handed": -2, "blow smoke": -2, "blowing smoke": -2,
# "upper hand": 1, "break a leg": 2,
# "cooking with gas": 2, "in the black": 2, "in the red": -2,
# "on the ball": 2,"under the weather": -2}
valence = self._least_check(valence, words_and_emoticons, i)
sentiments.append(valence)
return sentiments
Let's review the code when we are calling this method in the polarity_scores().
- sentiments = self.sentiment_valence(valence, sentitext, item, i, sentiments)
"valence" is 0; "item" is the current word; "i" is the index of current word in the text; "sentiments" is a list of sentiment values up to the previous word.
Keep going on...
is_cap_diff is a booling value.
- If it is True, the word list is a mixture of all uppercase words and ordinary words, such as ['HELLO','world'].
- However, if there is "no total-uppercase words in the list" or "all words are total-uppercase, which leads to no emphasis on some individual words", it'll be False, such as ['Hello','World] or ['HELLO','WORLD'].
words_and_emoticons is the clean token list of the text without puctuations.
item_lowercase is the lowercase form of the current word.
If the item_lowercase is not in lexicon (database), the valence of the current word is 0. If it is in our lexicon, then we can get the valence from our lexicon database. Then depending on the context, we will also slightly adjust its value.
- If the current word is total-uppercase and is_cap_diff is True, current word is a emphasis in the text, we need to add or substract a constant value C_INCR based on its valence.
- Next "For" loop is interesting, it updates the valence of the current word again based on the previous three words! Loop three times to see if the three words in front of the current word are in the lexicon database. Because all booster words are not in lexicon database, but in BOOSTER_DICT variable.
- scalar_inc_dec() method is to check if the preceding words increase, decrease, or negate/nullify the valence. (Check booster word, uppercase emphasis and currenr word's valence)
- _never_check(): Detection and corresponding schema, if "never" exists on previous three words.
- _idioms_check(): Detection and corresponding schema, if context 3 words make up an idiom.
- _least_check()
Summary Step:
- Get basic valence of the current word from the lexicon database
- 1st update on valence (uppercase emphsis): if the current word is uppercased compared with other words, it is an emphsis word. Add or substract an scalar value C_INCR based on positive or negtive current valence.
- 2nd update on valence (context booster): if the previous three words exists booster words, which are included in BOOSTER_DICT, it is also an emphsis to current word. Calculate a scalar value and add or substract to current valence.
- Rule 1: The booster word also applies to uppercase emphsis rule.
- Rule 2: Neighboring word has 100% influence. Booster word that is two words distance away from the current has 95% influence. Similarly, three words distance has 90% influence.
- 3rd update on valence (context never)
- 4th update on valence (context idioms)
- 5th update on valence (context least)
- Append lastest current word's valence to the sentiments list.
Remember: There are only 7502 token in the lexicon database.If the word in the text is not included in the lexicon database, it doesn't have valence (or sentiment / it is a nerual word). But these words may affect subsequent words' valence.
3. Method "score_valence()":
def score_valence(self, sentiments, text):
if sentiments:
sum_s = float(sum(sentiments))
# compute and add emphasis from punctuation in text
punct_emph_amplifier = self._punctuation_emphasis(sum_s, text)
if sum_s > 0:
sum_s += punct_emph_amplifier
elif sum_s < 0:
sum_s -= punct_emph_amplifier
compound = self.constants.normalize(sum_s)
# discriminate between positive, negative and neutral sentiment scores
pos_sum, neg_sum, neu_count = self._sift_sentiment_scores(sentiments)
if pos_sum > math.fabs(neg_sum):
pos_sum += punct_emph_amplifier
elif pos_sum < math.fabs(neg_sum):
neg_sum -= punct_emph_amplifier
total = pos_sum + math.fabs(neg_sum) + neu_count
pos = math.fabs(pos_sum / total)
neg = math.fabs(neg_sum / total)
neu = math.fabs(neu_count / total)
else:
compound = 0.0
pos = 0.0
neg = 0.0
neu = 0.0
sentiment_dict = {
"neg": round(neg, 3),
"neu": round(neu, 3),
"pos": round(pos, 3),
"compound": round(compound, 4),
}
return sentiment_dict
If sentiments is not None:
sum_s is the sum of all word valence in the sentiments list.
punct_emph_amplifier is also a scalar that used to update sum_s value. It is based on counts of "!" and "?".
According to the overall sentiment value, add or substract punct_emph_amplifier value to the sum_s.
compound is the normalize of sum_s. compound = sum_s/sqrt(sum_s^2+15)
def normalize(self, score, alpha=15):
"""
Normalize the score to be between -1 and 1 using an alpha that
approximates the max expected value
"""
norm_score = score / math.sqrt((score * score) + alpha)
return norm_score
_sift_sentiment_scores()
def _sift_sentiment_scores(self, sentiments):
# want separate positive versus negative sentiment scores
pos_sum = 0.0
neg_sum = 0.0
neu_count = 0
for sentiment_score in sentiments:
if sentiment_score > 0:
pos_sum += (
float(sentiment_score) + 1
) # compensates for neutral words that are counted as 1
if sentiment_score < 0:
neg_sum += (
float(sentiment_score) - 1
) # when used with math.fabs(), compensates for neutrals
if sentiment_score == 0:
neu_count += 1
return pos_sum, neg_sum, neu_count
_sift_sentiment_scores() counts the number of pos, neg and neu words. And for pos words and neg words, their latest valences are also added into pos_sum and neg_sum.
pos_sum, neg_sum and neu_count also need to be update based on punct_emph_amplifier.
The sum of pos, neg and neu is one.
Class "SentiText"
class SentiText:
"""
Identify sentiment-relevant string-level properties of input text.
"""
def __init__(self, text, punc_list, regex_remove_punctuation):
if not isinstance(text, str):
text = str(text.encode("utf-8"))
self.text = text
self.PUNC_LIST = punc_list
self.REGEX_REMOVE_PUNCTUATION = regex_remove_punctuation
self.words_and_emoticons = self._words_and_emoticons()
# doesn't separate words from
# adjacent punctuation (keeps emoticons & contractions)
self.is_cap_diff = self.allcap_differential(self.words_and_emoticons)
def _words_plus_punc(self):
"""
Returns mapping of form:
{
'cat,': 'cat',
',cat': 'cat',
}
"""
no_punc_text = self.REGEX_REMOVE_PUNCTUATION.sub("", self.text)
# removes punctuation (but loses emoticons & contractions)
words_only = no_punc_text.split()
# remove singletons
words_only = set(w for w in words_only if len(w) > 1)
# the product gives ('cat', ',') and (',', 'cat')
punc_before = {"".join(p): p[1] for p in product(self.PUNC_LIST, words_only)}
punc_after = {"".join(p): p[0] for p in product(words_only, self.PUNC_LIST)}
words_punc_dict = punc_before
words_punc_dict.update(punc_after)
return words_punc_dict
def _words_and_emoticons(self):
"""
Removes leading and trailing puncutation
Leaves contractions and most emoticons
Does not preserve punc-plus-letter emoticons (e.g. :D)
"""
wes = self.text.split()
words_punc_dict = self._words_plus_punc()
wes = [we for we in wes if len(we) > 1]
for i, we in enumerate(wes):
if we in words_punc_dict:
wes[i] = words_punc_dict[we]
return wes
def allcap_differential(self, words):
"""
Check whether just some words in the input are ALL CAPS
:param list words: The words to inspect
:returns: `True` if some but not all items in `words` are ALL CAPS
"""
is_different = False
allcap_words = 0
for word in words:
if word.isupper():
allcap_words += 1
cap_differential = len(words) - allcap_words
if 0 < cap_differential < len(words):
is_different = True
return is_different
Class "VaderConstants"
class VaderConstants:
"""
A class to keep the Vader lists and constants.
"""
##Constants##
# (empirically derived mean sentiment intensity rating increase for booster words)
B_INCR = 0.293
B_DECR = -0.293
# (empirically derived mean sentiment intensity rating increase for using
# ALLCAPs to emphasize a word)
C_INCR = 0.733
N_SCALAR = -0.74
NEGATE = {
"aint",
"arent",
"cannot",
"cant",
"couldnt",
"darent",
...,
}
# booster/dampener 'intensifiers' or 'degree adverbs'
# http://en.wiktionary.org/wiki/Category:English_degree_adverbs
BOOSTER_DICT = {
"absolutely": B_INCR,
"amazingly": B_INCR,
"awfully": B_INCR,
"completely": B_INCR,
"considerably": B_INCR,
"decidedly": B_INCR,
...
"very": B_INCR,
"almost": B_DECR,
"barely": B_DECR,
"kind of": B_DECR,
...
"sort of": B_DECR,
"sorta": B_DECR,
"sortof": B_DECR,
"sort-of": B_DECR,
}
# check for special case idioms using a sentiment-laden keyword known to SAGE
SPECIAL_CASE_IDIOMS = {
"the shit": 3,
"the bomb": 3,
"bad ass": 1.5,
"yeah right": -2,
"cut the mustard": 2,
"kiss of death": -1.5,
"hand to mouth": -2,
}
# for removing punctuation
REGEX_REMOVE_PUNCTUATION = re.compile("[{0}]".format(re.escape(string.punctuation)))
PUNC_LIST = [
".",
"!",
"?",
",",
";",
":",
"-",
"'",
'"',
"!!",
"!!!",
"??",
"???",
"?!?",
"!?!",
"?!?!",
"!?!?",
]
def __init__(self):
pass
def negated(self, input_words, include_nt=True):
"""
Determine if input contains negation words
"""
neg_words = self.NEGATE
if any(word.lower() in neg_words for word in input_words):
return True
if include_nt:
if any("n't" in word.lower() for word in input_words):
return True
for first, second in pairwise(input_words):
if second.lower() == "least" and first.lower() != "at":
return True
return False
def normalize(self, score, alpha=15):
"""
Normalize the score to be between -1 and 1 using an alpha that
approximates the max expected value
"""
norm_score = score / math.sqrt((score * score) + alpha)
return norm_score
def scalar_inc_dec(self, word, valence, is_cap_diff):
"""
Check if the preceding words increase, decrease, or negate/nullify the
valence
"""
scalar = 0.0
word_lower = word.lower()
if word_lower in self.BOOSTER_DICT:
scalar = self.BOOSTER_DICT[word_lower]
if valence < 0:
scalar *= -1
# check if booster/dampener word is in ALLCAPS (while others aren't)
if word.isupper() and is_cap_diff:
if valence > 0:
scalar += self.C_INCR
else:
scalar -= self.C_INCR
return scalar
Database "vader_lexicon.txt"
We can take a quick look at the contents of the file "vader_lexicon.txt":
$: -1.5 0.80623 [-1, -1, -1, -1, -3, -1, -3, -1, -2, -1]
%) -0.4 1.0198 [-1, 0, -1, 0, 0, -2, -1, 2, -1, 0]
%-) -1.5 1.43178 [-2, 0, -2, -2, -1, 2, -2, -3, -2, -3]
&-: -0.4 1.42829 [-3, -1, 0, 0, -1, -1, -1, 2, -1, 2]
...
adorableness 2.5 0.67082 [2, 3, 3, 2, 3, 2, 1, 3, 3, 3]
adorably 2.1 0.7 [3, 1, 2, 3, 2, 2, 1, 3, 2, 2]
adoration 2.9 0.7 [3, 3, 3, 2, 3, 3, 4, 2, 4, 2]
adorations 2.2 0.87178 [2, 2, 3, 1, 3, 1, 3, 3, 1, 3]
...
The first column is words and emoticons, the second column is sentiment value. In class SentimentIntensityAnalyzer, method "make_lex_dict()" only uses the first two columns: word name and sentiment value.
What does 3rd column and 4th column represent?
How does these valence value come out?